Глава 7 Компонентная архитектура
7.1 Принципы модульной архитектуры
Платформа ЦДП построена на принципах модульной архитектуры, что обеспечивает гибкость, масштабируемость и возможность поэтапного внедрения. Модульный подход позволяет адаптировать систему под специфику конкретного предприятия, подключая только необходимые компоненты.
Ключевые принципы модульности:
1. Независимость модулей
Каждый модуль представляет собой самостоятельную функциональную единицу с чётко определённым интерфейсом взаимодействия. Модули могут разрабатываться, тестироваться и обновляться независимо друг от друга, что снижает риски при внедрении изменений.
2. Слабая связанность (Loose Coupling)
Модули взаимодействуют через стандартизированные API, что минимизирует зависимости между компонентами. Изменение внутренней реализации одного модуля не требует модификации других модулей, если интерфейс остаётся неизменным.
3. Высокая связность (High Cohesion)
Внутри каждого модуля сосредоточена логически связанная функциональность. Например, модуль прогнозирования содержит все компоненты, необходимые для построения и выполнения прогнозных моделей.
4. Переиспользуемость
Модули проектируются как универсальные компоненты, которые могут применяться в различных проектах и отраслях. Например, модуль балансовых расчётов используется как в химической промышленности, так и в АПК.
5. Масштабируемость
Модульная архитектура позволяет горизонтально масштабировать отдельные компоненты в зависимости от нагрузки. Вычислительно-интенсивные модули могут разворачиваться на выделенных серверах с повышенной производительностью.
Типовые модули платформы:
- Модуль управления данными — сбор, нормализация, хранение и предоставление доступа к данным;
- модуль моделирования — построение структурно-технологических схем и балансовых моделей;
- модуль оптимизации — решение задач линейного и нелинейного программирования;
- модуль прогнозирования — временные ряды, машинное обучение, сценарный анализ;
- модуль визуализации — информационные панели, отчёты, интерактивные графики;
- модуль интеграции — REST API, ETL-процессы, коннекторы к внешним системам;
- модуль администрирования — управление пользователями, правами доступа, конфигурацией.
Модульная архитектура обеспечивает возможность поэтапного внедрения: заказчик может начать с базовых модулей (управление данными, визуализация) и постепенно подключать расширенную функциональность (оптимизация, машинное обучение) по мере готовности и необходимости.
7.2 Технические компоненты системы
Компонентная архитектура ЦДП основана на микросервисном подходе, где каждый компонент отвечает за свою область функциональности. Программное обеспечение выполнено на основе библиотек с открытым кодом R и включает модули высокопроизводительных расчетов на Java и C++.
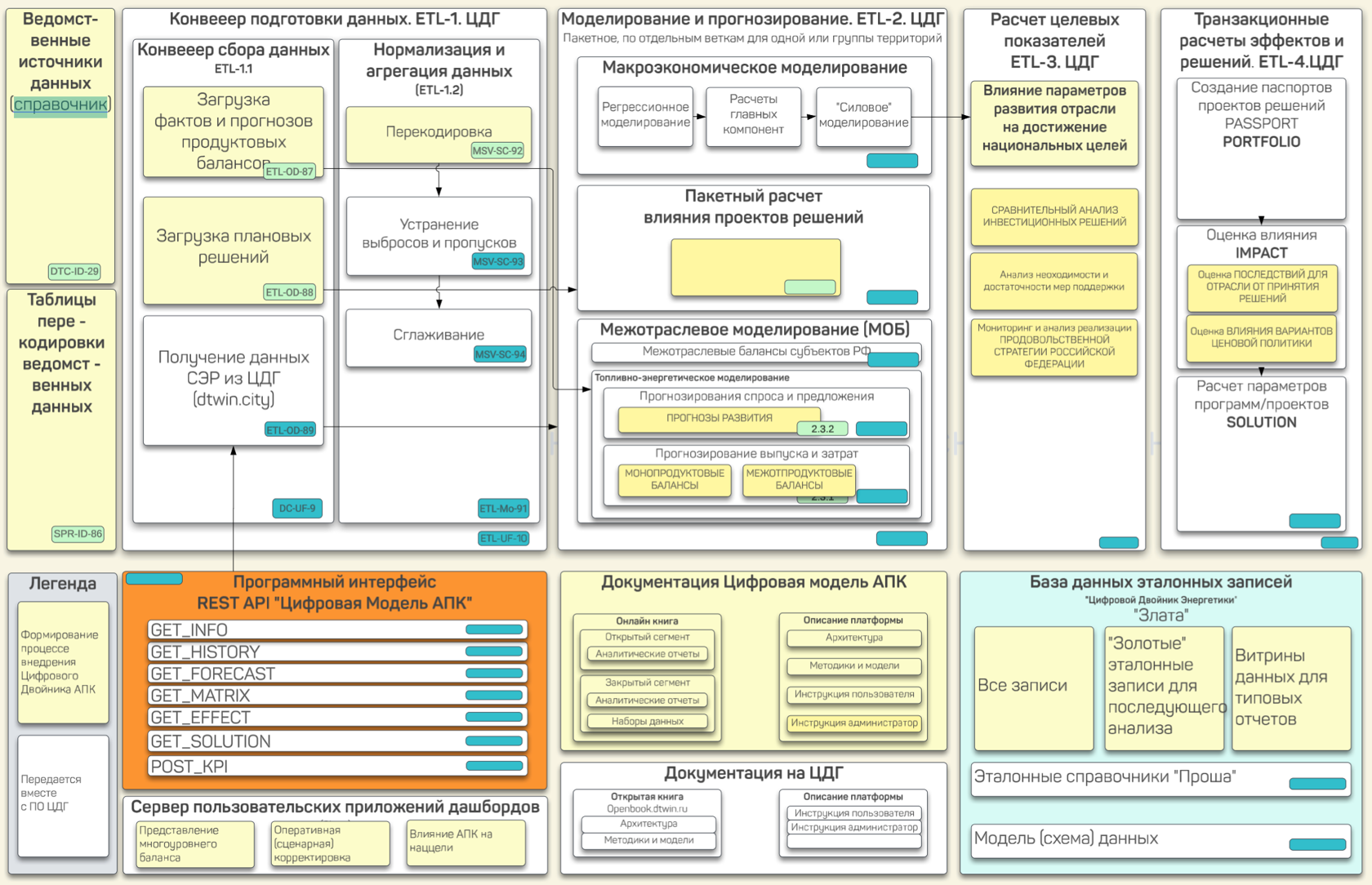
Рисунок 37 — Компонентная архитектура ЦДП
Микросервисная архитектура обеспечивает масштабируемость и гибкость, что позволяет динамически добавлять или отключать компоненты без влияния на работу других частей системы.
7.3 Этапы обработки данных
7.3.1 Этап получения и обработки данных
ETL (Extract, Transform, Load): Технология ETL отвечает за сбор данных из различных источников, их трансформацию и загрузку в центральное хранилище. Данные могут поступать как из внутренних систем предприятия, так и из внешних источников (например, Росстат, ФНС, API).
API-интеграция: Позволяет системе получать данные в реальном времени из различных источников, что обеспечивает актуальность расчетов и анализа.
Нормализация данных: Система автоматически нормализует данные, приводя их к единому стандарту и устраняя дубли, пропуски и ошибки в форматах.
На практике система объединяет открытые и закрытые источники данных: Росстат, ФНС, ФТС, ФГИС «Зерно», биржевые данные (FOREX, CME, CBOT), ВТО, данные по социально-экономическому развитию стран мира. На рисунке ниже показан конвейер сбора данных для реализации в АПК.
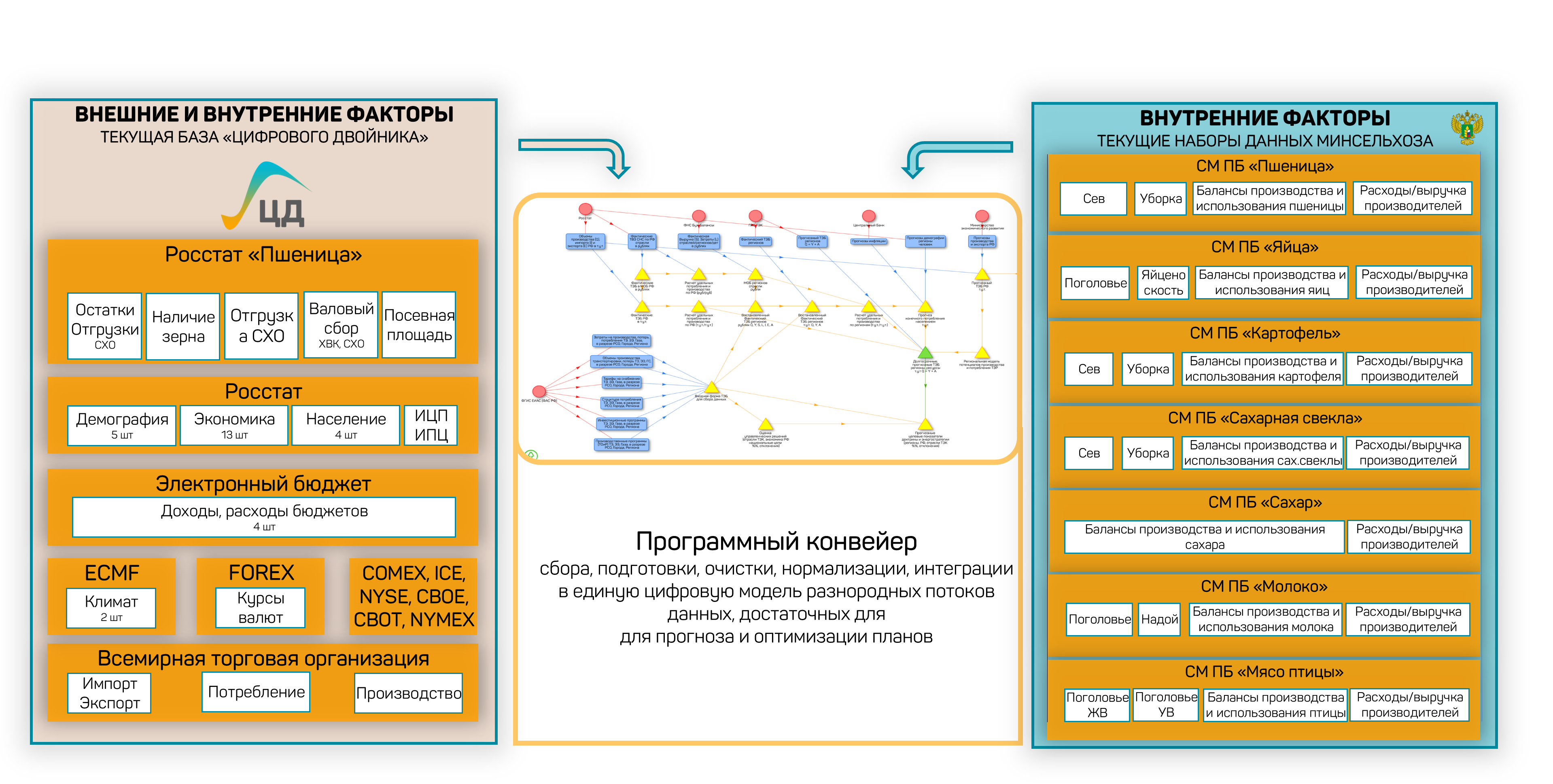
Рисунок 38 — Источники данных и конвейер сбора: открытые и закрытые источники
7.3.2 Этап расчетов и аналитики
Java и C++: Для проведения высокопроизводительных расчетов используются модули на Java и C++, что позволяет обрабатывать большие объемы данных с минимальными задержками.
R (Posit): Обеспечивает поддержку сложных статистических и математических моделей, необходимых для сценарного моделирования, факторного анализа и прогнозирования.
Targets: Используется для организации расчетных узлов и управления их зависимостями. Эта технология отслеживает актуальность данных и расчетов, поддерживает версионность расчетных моделей и обеспечивает многократные параллельные вычисления.
Балансовые модели: Система поддерживает модели межотраслевых и межтерриториальных балансов, а также ресурсно-балансовую модель, которые используются для оценки потребностей предприятия в ресурсах и их оптимального распределения.
На примере производства пшеницы технологическая схема охватывает полный цикл: хранение импортной продукции, выращивание и уборка урожая, реализация, хранение, кормление скота, экспорт и переработка. Каждый блок связан с натуральными, стоимостными и прогнозными показателями.
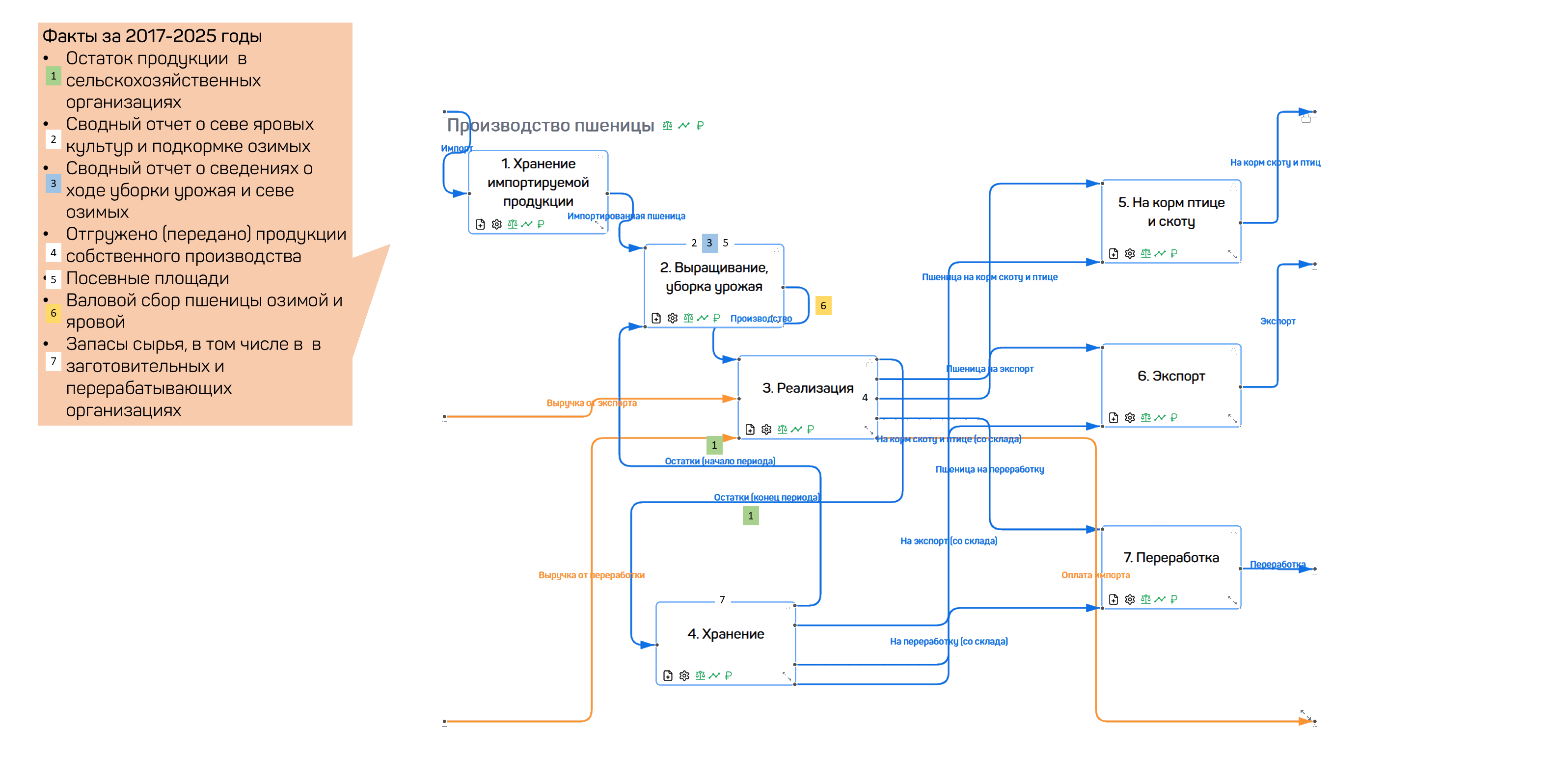
Рисунок 39 — Технологическая схема производства пшеницы с потоками ресурсов
7.4 Слой данных
7.4.1 PostgreSQL - Реляционная СУБД
Назначение: Хранение транзакционных данных и метаданных системы.
Хранимые данные:
- Справочники и классификаторы
- Данные пользователей и прав доступа
- Конфигурация системы
- Транзакционные данные
- Метаданные моделей
Характеристики:
- Версия: PostgreSQL 14+
- Репликация: Master-Slave
- Резервное копирование: Ежедневно
- Производительность: До 10,000 TPS
7.4.2 ClickHouse - Аналитическая СУБД
Назначение: Хранение больших объемов аналитических данных.
Хранимые данные:
- Временные ряды (производство, продажи, цены)
- Агрегированные показатели
- Логи и события системы
- Результаты расчетов
Характеристики:
- Версия: ClickHouse 22+
- Сжатие данных: До 10x
- Скорость запросов: Миллионы строк/сек
- Партиционирование: По времени
7.5 Слой интеграции
7.5.1 ETL-модуль
Назначение: Извлечение, трансформация и загрузка данных.
Компоненты:
1. Коннекторы:
- REST API клиенты
- ODBC/JDBC драйверы
- Парсеры файлов (Excel, CSV, XML)
- Извлечение данных с веб-страниц (web scraping)
2. Трансформаторы:
- Нормализация данных
- Валидация и очистка
- Обогащение данных
- Агрегация
3. Загрузчики:
- Пакетная загрузка
- Потоковая загрузка
- Инкрементальная загрузка
4. Технологии:
- Apache NiFi для визуального дизайна потоков
- Python для кастомных трансформаций
- Apache Kafka для потоковой обработки
7.6 Слой бизнес-логики
7.6.1 Аналитический модуль (R/Posit)
Назначение: Статистический анализ и моделирование.
Возможности:
- Описательная статистика
- Временные ряды (forecast, prophet)
- Корреляционный анализ
- Регрессионный анализ
- Кластерный анализ
Библиотеки:
tidyverse- обработка данныхforecast- прогнозированиеtargets- управление вычислениямиshiny- интерактивные приложенияggplot2- визуализация
Производительность:
- Параллельные вычисления
- Кэширование результатов
- Инкрементальные расчеты
7.6.2 Модуль машинного обучения и оптимизации (Python)
Назначение: Машинное обучение и оптимизация.
Использование технологий искусственного интеллекта в аналитических расчётах организовано в 5 этапов: предобработка и создание единой ресурсно-балансовой модели (NLP/BERT, Anomaly Detection, AutoML), дообучение модели (LSTM/GRU, XGBoost/CatBoost, Graph Neural Networks), прогнозирование (Meta-Learning/Stacking, Bayesian Inference), сценарии и риски (Reinforcement Learning, VAE/GAN, Monte Carlo), оптимизация решений (SHAP/LIME, Real-time Monitoring).
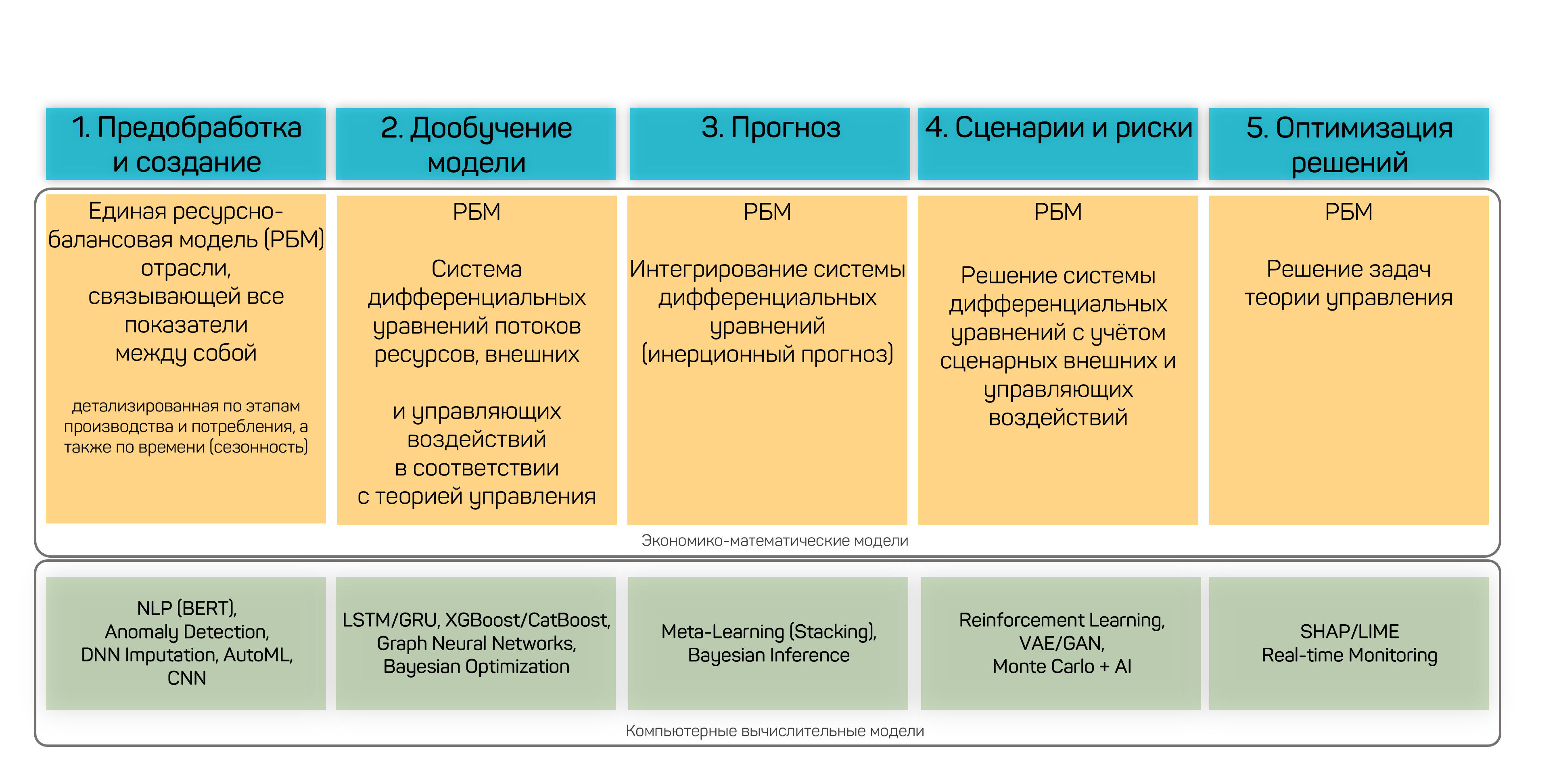
Рисунок 40 — Использование технологий ИИ для аналитических расчётов: 5 этапов от предобработки до оптимизации
Возможности:
Машинное обучение:
- Обучение с учителем (supervised learning) — регрессия, классификация
- Обучение без учителя (unsupervised learning) — кластеризация
- Прогнозирование временных рядов
- Глубокое обучение (deep learning, опционально)
Оптимизация:
- Линейное программирование
- Целочисленное программирование
- Нелинейная оптимизация
- Генетические алгоритмы
Библиотеки:
scikit-learn- ML алгоритмыxgboost,lightgbm- градиентный бустингscipy.optimize- оптимизацияpulp,pyomo- математическое программированиеpandas,numpy- обработка данных
7.6.3 Вычислительный модуль (Java/C++)
Назначение: Высокопроизводительные вычисления.
Применение:
- Симуляции производственных процессов
- Ресурсно-балансовые расчеты
- Обработка больших объемов данных
- Критичные по времени расчеты
Технологии:
- Java 17+ для бизнес-логики
- C++ для вычислительно-сложных задач
- Apache Spark для распределенных вычислений
7.7 Слой API
7.7.1 REST API сервисы
Назначение: Предоставление функциональности через HTTP API.
Платформа ЦДП предоставляет полнофункциональный REST API для интеграции с внешними системами, автоматизации процессов и программного доступа к данным и расчётам. API построен по принципам RESTful архитектуры и поддерживает стандартные HTTP-методы (GET, POST, PUT, DELETE).
Документация API:
Полная интерактивная документация API доступна по адресу: https://207api.dtwin.ru/docs/
Документация включает:
- Описание всех эндпоинтов с примерами запросов и ответов;
- интерактивную консоль для тестирования API;
- схемы данных и модели объектов;
- коды ошибок и их обработку;
- примеры интеграции на различных языках программирования.
Основные группы эндпоинтов:
# Данные и справочники
GET /api/v1/data/documents # Список документов
GET /api/v1/data/kpi # KPI показатели
POST /api/v1/data/import # Импорт данных
GET /api/v1/data/dictionaries # Справочники
# Аналитика и расчёты
POST /api/v1/analytics/forecast # Прогнозирование
POST /api/v1/analytics/optimize # Оптимизация
GET /api/v1/analytics/results # Результаты расчётов
POST /api/v1/analytics/scenarios # Сценарное моделирование
# Внешние факторы
GET /api/v1/factors/list # Список внешних факторов
POST /api/v1/factors/update # Обновление факторов
GET /api/v1/factors/history # История изменений
# Мониторинг и визуализация
GET /api/v1/monitor/dashboard # Данные информационной панели
GET /api/v1/monitor/alerts # Оповещения
GET /api/v1/monitor/sts # СТС данные
# Администрирование
GET /api/v1/admin/users # Пользователи
POST /api/v1/admin/config # Конфигурация
GET /api/v1/admin/logs # Логи системыСистема сопровождаемых внешних факторов:
Платформа ЦДП включает подсистему управления внешними факторами, влияющими на производственные и экономические показатели предприятия. Система позволяет:
- Отслеживать изменения макроэкономических показателей (курсы валют, цены на сырьё, индексы);
- автоматически обновлять данные из внешних источников через API;
- оценивать влияние внешних факторов на ключевые показатели предприятия;
- проводить сценарный анализ при изменении внешних условий;
- формировать раннее предупреждение о критических изменениях.
Внешние факторы интегрируются в расчётные модели и автоматически учитываются при прогнозировании и оптимизации.
Технологии и стандарты:
- Node.js / Express для API сервера;
- Swagger/OpenAPI 3.0 для документации;
- JWT (JSON Web Tokens) для аутентификации;
- OAuth 2.0 для авторизации внешних приложений;
- Rate limiting для защиты от перегрузок;
- CORS для кросс-доменных запросов.
7.8 Слой представления
7.8.1 Web-приложение
Технологии:
Frontend Framework:
- React 18+ с TypeScript
- Redux для state management
- React Router для навигации
UI Components:
- Material-UI для компонентов
- Styled Components для стилей
- Formik для форм
Визуализация:
- D3.js для кастомных графиков
- Plotly.js для интерактивных графиков
- Recharts для простых диаграмм
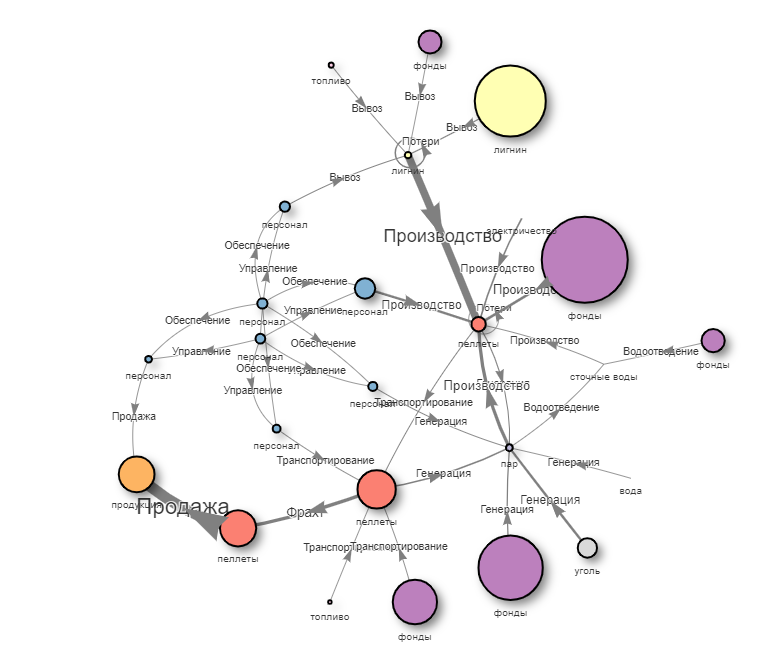
Рисунок 41 — Динамический граф производственных потоков: визуализация ресурсных связей предприятия
Build Tools:
- Vite для быстрой сборки
- ESLint для линтинга
- Prettier для форматирования
7.9 Архитектура платформ
Архитектура платформы включает два основных контура:
1. Цифровой двойник города (анализ внешних факторов, макроэкономическое моделирование); 2. Цифровой двойник предприятия (производственные балансы, оптимизация).
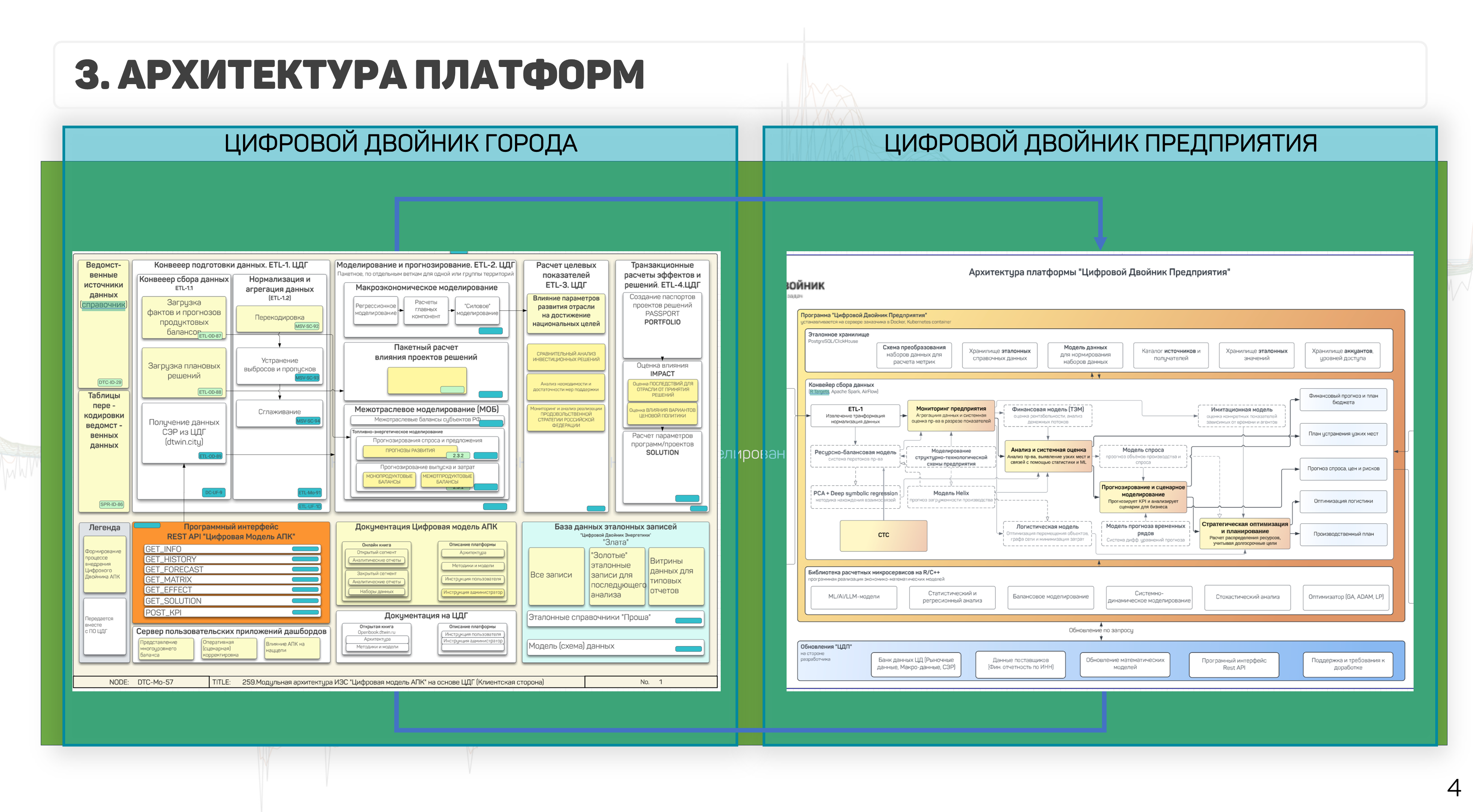
Рисунок 42 — Архитектура платформ: Цифровой двойник города и Цифровой двойник предприятия
Технический стек Единой цифровой платформы включает подсистемы аутентификации (Nginx, Blitz Identity Provider), администрирования (RabbitMQ, Apache Tomcat, Spring Boot), сбора данных (Vue.js, PHP, PostgreSQL), аналитических расчётов (C++, jQuery, БД проприетарного формата), интеграции (GosJava), хранилища (Angular, Golang, PostgreSQL, Redis, Nginx).
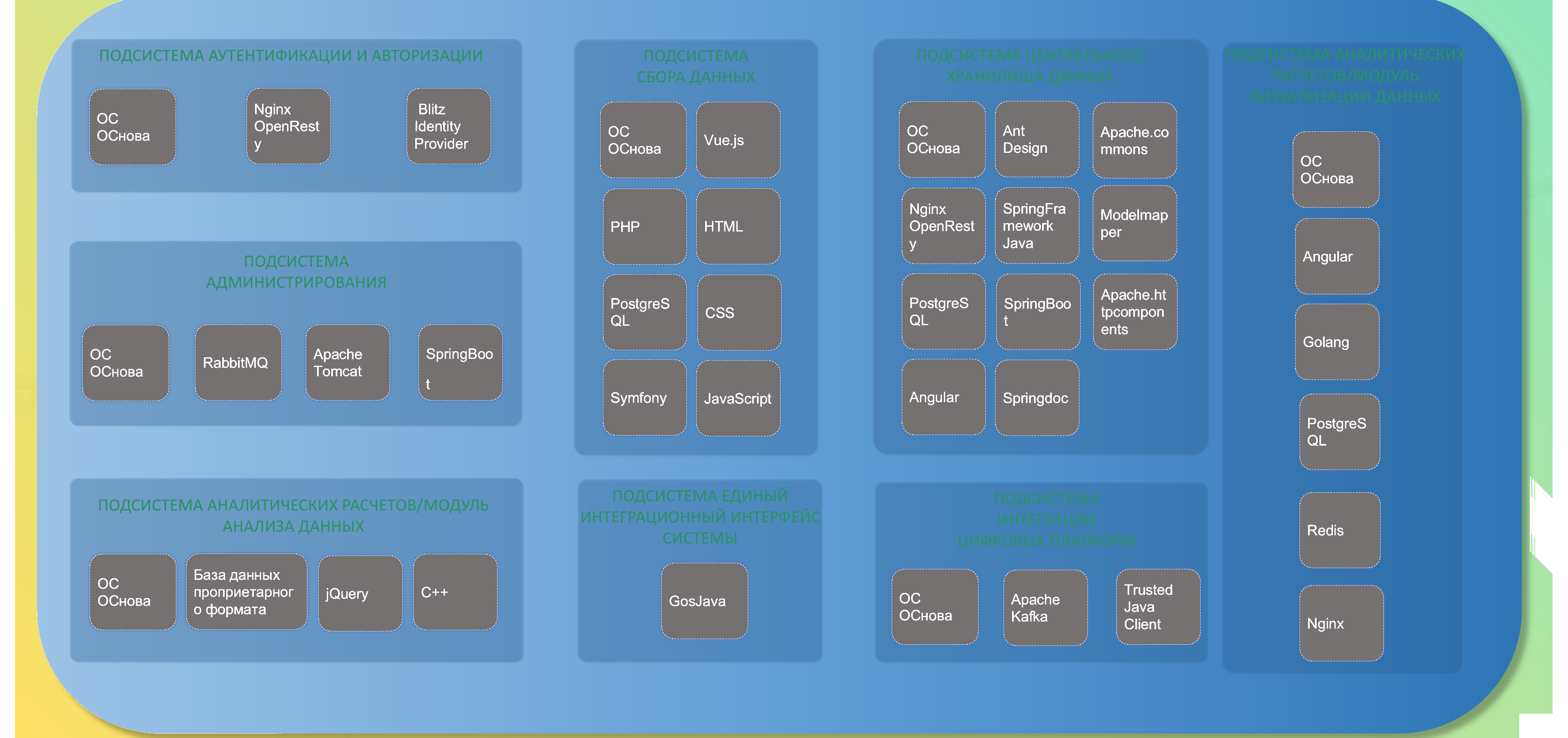
Рисунок 43 — Технический стек Единой цифровой платформы
7.10 Инфраструктурные компоненты
7.10.1 Мониторинг и логирование
Prometheus + Grafana:
- Метрики производительности
- Использование ресурсов
- Время отклика API
- Кастомные метрики
ELK Stack (Elasticsearch, Logstash, Kibana):
- Централизованное логирование
- Поиск по логам
- Визуализация событий
- Анализ ошибок
7.10.2 Кэширование
Redis:
- Кэш API ответов
- Сессии пользователей
- Временные данные
- Очереди задач
Memcached:
- Кэш результатов расчетов
- Кэш запросов к БД
7.10.3 Балансировка нагрузки
NGINX:
- Load balancing
- SSL termination
- Reverse proxy
- Статические файлы
HAProxy (опционально):
- TCP/HTTP load balancing
- Health checks
- Статистика
7.10.4 Контейнеризация
Docker:
- Контейнеры для всех сервисов
- Изоляция зависимостей
- Быстрое развертывание
- Версионирование образов
Docker Compose:
- Оркестрация локальной разработки
- Декларативная конфигурация
Kubernetes (опционально):
- Оркестрация в продакшене
- Автомасштабирование
- Rolling updates
- Self-healing
7.11 Безопасность
7.11.1 Аутентификация и авторизация
OAuth 2.0 / OpenID Connect:
- Единый вход (SSO)
- Токены доступа
- Refresh tokens
JWT (JSON Web Tokens):
- Stateless аутентификация
- Claims для прав доступа
- Истечение токенов
RBAC (Role-Based Access Control):
- Роли пользователей
- Права доступа
- Иерархия ролей